| Questão de Entrevista |
| País: Irlanda |
Tipo: Técnica |
Assunto: Banco de Dados |
| Ramo de negócio da empresa: Financeiro (Banco) |
Grau de Dificuldade: Média |
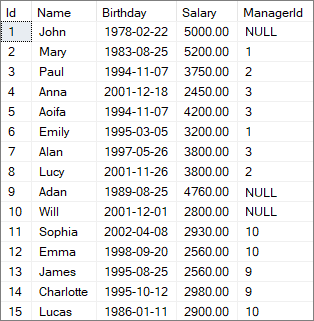
Data a tabela Employee, escreva consultas que retorne:
- O nome e o salário dos empregados que recebem mais do que os seus gerentes (manager) diretos, ordenando o resultado pelo salário de forma decrescente
- O nome dos empregados que possuem exatamente outros dois empregados com o mesmo dia e mês de aniversário.

Abaixo o script para criar e inserir os dados da tabela (padrão ANSI, pode ser usado em qualquer banco de dados)
-- cria a tabela Employee (Empregado)
-- com chave primária nomeada como PK_Employee
CREATE TABLE dbo.Employee(
Id int NOT NULL,
Name varchar(50) NOT NULL,
Birthday datetime NOT NULL,
Salary numeric(18, 2) NOT NULL,
ManagerId int,
CONSTRAINT PK_Employee
PRIMARY KEY (Id)
)
-- cria uma chave estrangeira (foreign key)
-- relacionando o gerente (ManagerId) ao empregado (Id)
ALTER TABLE dbo.Employee
WITH CHECK ADD CONSTRAINT FK_Employee_Employee
FOREIGN KEY(ManagerId)
REFERENCES dbo.Employee (Id)
--insere registros na table a Employee
INSERT INTO Employee
(Id,Name,Birthday,Salary,ManagerId)
VALUES (1, 'John', '1978-02-22', 5000, null)
-- como todos os campos estão sendo usados, podemos simplificar
-- o comando ocultado p nome das colunas na instrução INSERT
INSERT INTO Employee VALUES (2, 'Mary', '1983-08-25', 5200, 1)
INSERT INTO Employee VALUES (3, 'Paul', '1994-11-07', 3750, 2)
INSERT INTO Employee VALUES (4, 'Anna', '2001-12-18', 2450, 3)
INSERT INTO Employee VALUES (5, 'Aoifa', '1994-11-07', 4200, 3)
INSERT INTO Employee VALUES (6, 'Emily', '1995-03-05', 3200, 1)
INSERT INTO Employee VALUES (7, 'Alan', '1997-05-26', 3800, 3)
INSERT INTO Employee VALUES (8, 'Lucy', '2001-11-26', 3800, 2)
INSERT INTO Employee VALUES (9, 'Adan', '1989-08-25', 4760, null)
INSERT INTO Employee VALUES (10, 'Will', '2001-12-01', 2800, null)
INSERT INTO Employee VALUES (11, 'Sophia', '2002-04-08', 2930, 10)
INSERT INTO Employee VALUES (12, 'Emma', '1998-09-20', 2560, 10)
INSERT INTO Employee VALUES (13, 'James', '1995-08-25', 2560, 9)
INSERT INTO Employee VALUES (14, 'Charlotte', '1995-10-12', 2980, 9)
INSERT INTO Employee VALUES (15, 'Lucas', '1986-01-11', 2900, 10)
Vamos a questão 1: retornar o nome e o salário dos empregados que recebem mais do que os seus gerentes diretos, ordenando os registros pelo salário de forma decrescente.
Analisando os dados nota-se que a coluna ManagerId é uma auto-referência para a tabela Employee, ou seja, indica o registro na tabela que se refere ao gerente da pessoa em questão. Por exemplo: John (Id = 1) não tem um gerente direto, pois seu ManagerId é nulo. Já Mary (Id= 2) é subordinada a John, pois seu ManagerId é igual 1, que é o Id de John. Mary tem um salário de $5200, enquanto John tem um salário de $5000, logo Mary deve ser listada.
Uma das formas de resolver este problema é usando um subselect e comparar o salário do cada registro da tabela Employee com o salário do seu respectivo gerente. Como quem não tem gerente direto não precisa ser listado, por questões de desempenho pode-se adicionar um filtro para ignorar estas pessoas, com isto o subselect não será executado nestes casos (o engine do banco de dados sabe que uma expressão com subselect é mais cara, computacionalmente falando, que uma expressão que usa apenas um campo da própia tabela, como o operador condicional AND (E) exige que as duas expressões sejam verdadeira para ser verdadeiro, ele executa primeiro a condição e.ManagerId is not null e ignora a segunda expressão se a primeira for falsa):
select Name, Salary
from Employee e
where e.ManagerId is not null
and e.Salary > (select Salary
from Employee e2
where e2.Id = e.ManagerId)
order by e.Salary desc
Executando o comando acima:
| Name |
Salary |
| Mary |
5200.00 |
| Aoifa |
4200.00 |
| Alan |
3800.00 |
| Sophia |
2930.00 |
| Lucas |
2900.00 |
Outra forma de resolver o problema é fazer um INNER JOIN da tabela Employee com ela mesma. Esta forma, além de ter melhor performance, permite listar o nome e o salaário do gerente, o que facilita a verificação do resultado (isto está fora do escopo do exercício inicial, se o exercício for corrigido eletronicamente, devolva exatamente o que se pede. Se for uma programação em par – entrevistador e entrevistado – você pode usar mas deve destacar o que está fazendo):
select e.Name, e.Salary, e2.Name Manager, e2.Salary
from Employee e
inner join (select Id, Name, Salary from Employee) e2
on e2.Id = e.ManagerId
where e.Salary > e2.Salary
order by e.Salary desc
Perceba que no exemplo acima a condição e.ManagerId is not null foi suprimida. Como foi usado um INNER JOIN, que obriga que o registro exista dos dois lados da junção, os registros com ManagerId = NULL são automaticamente descartados.
| Name |
Salary |
Manager |
Salary |
| Mary |
5200.00 |
John |
5000.00 |
| Aoifa |
4200.00 |
Paul |
3750.00 |
| Alan |
3800.00 |
Paul |
3750.00 |
| Sophia |
2930.00 |
Will |
2800.00 |
| Lucas |
2900.00 |
Will |
2800.00 |
Agora a questão 2: listar o nome nome dos empregados que possuem exatamente outros dois empregados com o mesmo dia e mês de aniversário.
Para responder a questão vamos usar a mesma base de comando da primeira opção de resposta da questão 1, com alterações na cláusula where da subconsulta. Para comprar os dias e meses foram usadas, respectivamente, as funções DAY e MONTH (estas funções são do SQL Server, consulte a documentação do seu banco de dados para encontrar a função equivalente).
select Name
from Employee e
where (select count(*)
from Employee e2
where e2.Id <> e.Id
and day(e2.Birthday) = day(e.Birthday)
and month(e2.Birthday) = month(e.Birthday)) = 2
O resultado é:
Note que Aoifa e Paul também fazem aniversário no mesmo dia e mês (07 de novembro), mas o exercício pede que sejam listadas apenas o empregados que possuem exatamente outros dois com o mesmo dia e mês de aniversário, por isto a inclusão da condição e2.Id <> e.Id na cláusula where da subconsulta.